Publications
2026
- 2026ABSTRACT CODE
Breaking the Curse of Dimensionality in Gaussian Process Training With Zeroth-Order Adaptive Perturbation
Richard Cornelius Suwandi, Feng Yin, Tsung-Hui Chang51th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026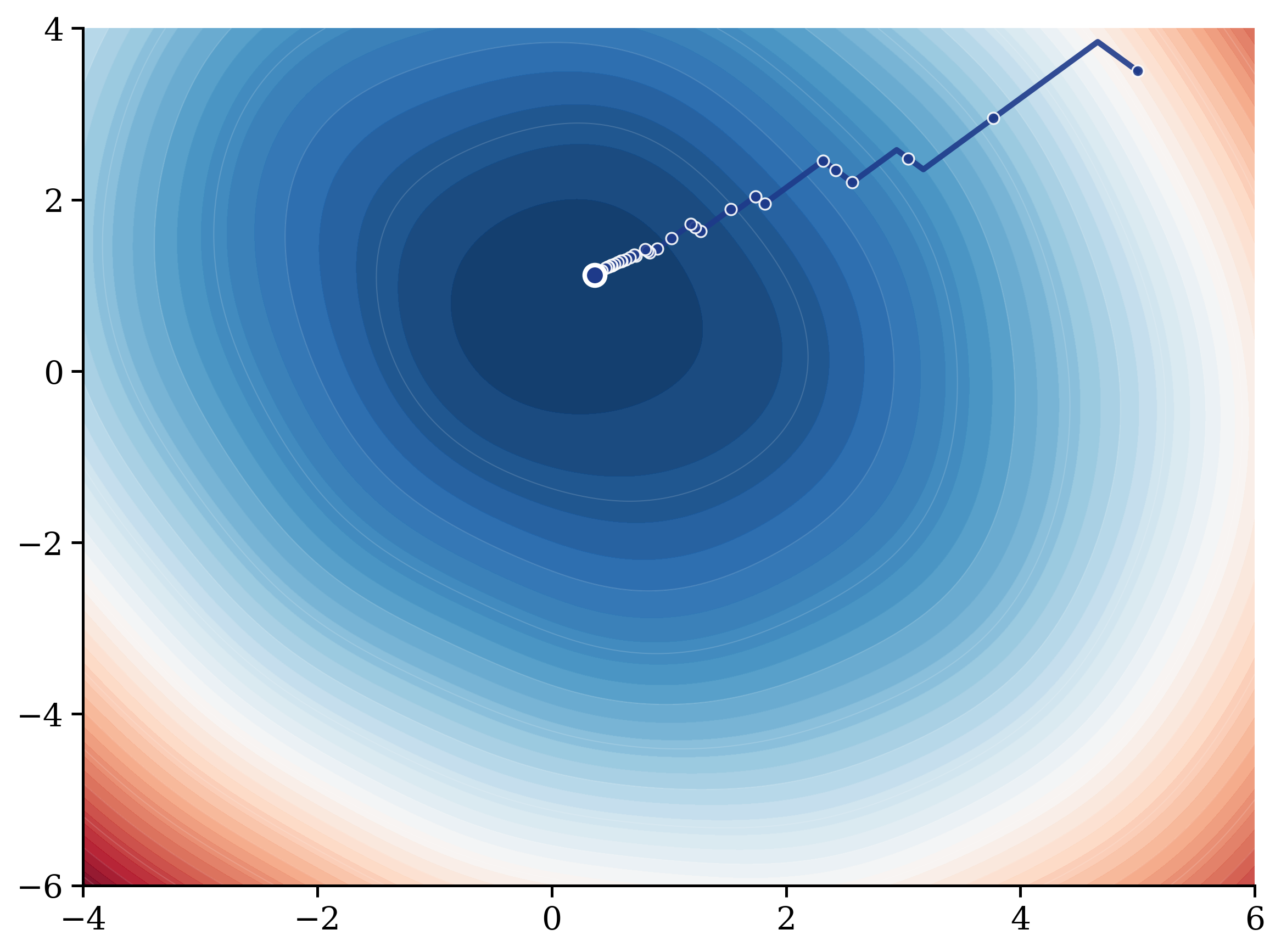
Abstract
Hyperparameter optimization remains a core challenge in training Gaussian processes (GPs), primarily due to the high computational cost and numerical instabilities associated with gradient-based optimizers. These issues are exacerbated in high-dimensional spaces, where the optimization landscapes become increasingly complex and difficult to navigate efficiently. We propose zeroth-order adaptive perturbation (ZAP), a scalable gradient-free algorithm that leverages simultaneous perturbations sampled from a Bernoulli distribution to obtain accurate gradient estimates with only two function evaluations per iteration, regardless of the hyperparameter dimensionality. Our theoretical analysis establishes that the gradient estimator is asymptotically unbiased and that ZAP converges to a stationary point under standard assumptions. Empirically, ZAP outperforms state-of-the-art gradient-based and gradient-free baselines on real-world datasets, achieving an average of 20 times reduction in mean-squared-error and a 118 times speedup in optimization time.
2025
-
Adaptive Kernel Design for Bayesian Optimization Is a Piece of CAKE with LLMs
Richard Cornelius Suwandi, Feng Yin, Juntao Wang, 3 more authors Renjie Li, Tsung-Hui Chang, Sergios Theodoridis39th Conference on Neural Information Processing Systems (NeurIPS), 2025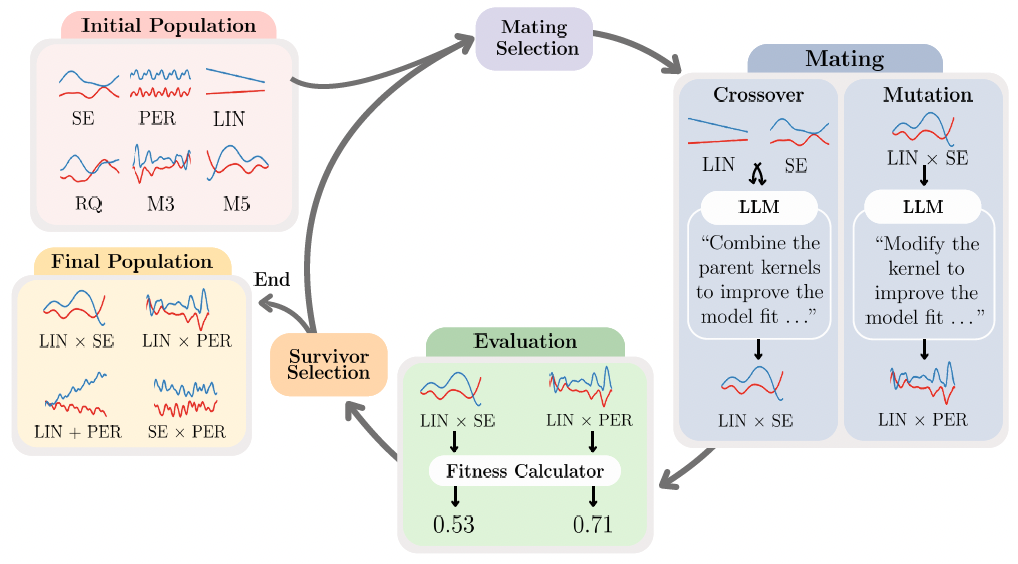
Abstract
The efficiency of Bayesian optimization (BO) relies heavily on the choice of the Gaussian process (GP) kernel, which plays a central role in balancing exploration and exploitation under limited evaluation budgets. Traditional BO methods often rely on fixed or heuristic kernel selection strategies, which can result in slow convergence or suboptimal solutions when the chosen kernel is poorly suited to the underlying objective function. To address this limitation, we propose a freshly-baked Context-Aware Kernel Evolution (CAKE) to enhance BO with large language models (LLMs). Concretely, CAKE leverages LLMs as the crossover and mutation operators to adaptively generate and refine GP kernels based on the observed data throughout the optimization process. To maximize the power of CAKE, we further propose BIC-Acquisition Kernel Ranking (BAKER) to select the most effective kernel through balancing the model fit measured by the Bayesian information criterion (BIC) with the expected improvement at each iteration of BO. Extensive experiments demonstrate that our fresh CAKE-based BO method consistently outperforms established baselines across a range of real-world tasks, including hyperparameter optimization, controller tuning, and photonic chip design. Our code is publicly available at https://github.com/richardcsuwandi/cake.
-
Sparsity-Aware Distributed Learning for Gaussian Processes with Linear Multiple Kernel
Richard Cornelius Suwandi, Zhidi Lin, Feng Yin, 2 more authors Zhiguo Wang, Sergios TheodoridisIEEE Transactions on Neural Networks and Learning Systems, 2025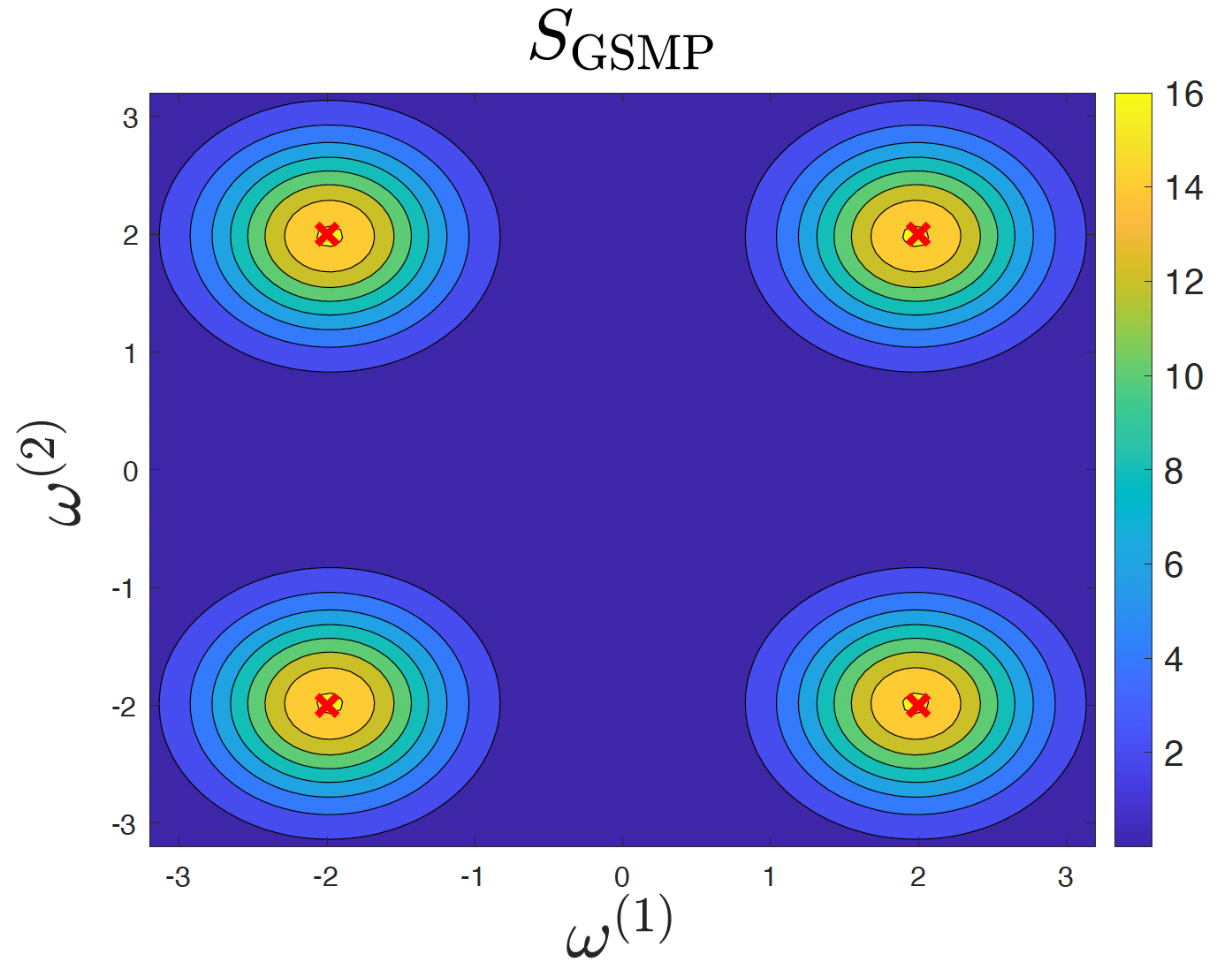
Abstract
Gaussian processes (GPs) stand as crucial tools in machine learning and signal processing, with their effectiveness hinging on kernel design and hyper-parameter optimization. This paper presents a novel GP linear multiple kernel (LMK) and a generic sparsity-aware distributed learning framework to optimize the hyper-parameters. The newly proposed grid spectral mixture (GSM) kernel is tailored for multi-dimensional data, effectively reducing the number of hyper-parameters while maintaining good approximation capabilities. We further demonstrate that the associated hyper-parameter optimization of this kernel yields sparse solutions. To exploit the inherent sparsity property of the solutions, we introduce the Sparse LInear Multiple Kernel Learning (SLIM-KL) framework. The framework incorporates a quantized alternating direction method of multipliers (ADMM) scheme for collaborative learning among multiple agents, where the local optimization problem is solved using a distributed successive convex approximation (DSCA) algorithm. SLIM-KL effectively manages large-scale hyper-parameter optimization for the proposed kernel, simultaneously ensuring data privacy and minimizing communication costs. Theoretical analysis establishes convergence guarantees for the learning framework, while experiments on diverse datasets demonstrate the superior prediction performance and efficiency of our proposed methods.
2022
-
Gaussian process regression with grid spectral mixture kernel: Distributed learning for multidimensional data
Richard Cornelius Suwandi, Zhidi Lin, Yiyong Sun, 3 more authors Zhiguo Wang, Lei Cheng, Feng Yin25th International Conference on Information Fusion (FUSION), 2022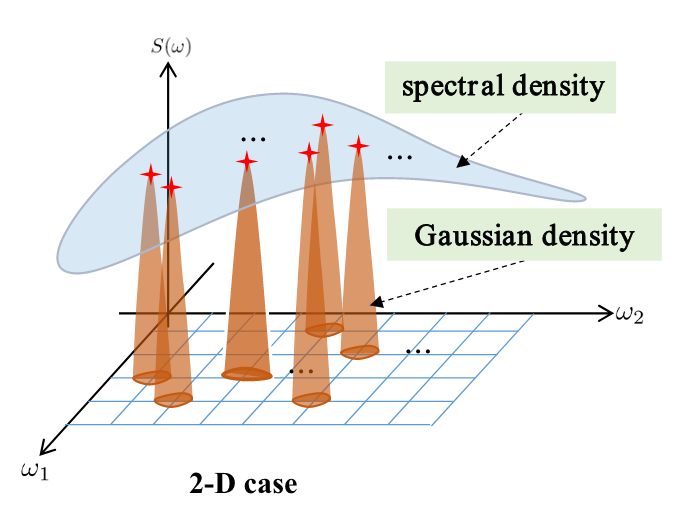
Abstract
Kernel design for Gaussian processes (GPs) along with the associated hyper-parameter optimization is a challenging problem. In this paper, we propose a novel grid spectral mixture (GSM) kernel design for GPs that can automatically fit multidimensional data with affordable model complexity and superior modeling capability. To alleviate the computational complexity due to the curse of dimensionality, we leverage a multicore computing environment to optimize the kernel hyper-parameters in a distributed manner. We further propose a doubly distributed learning algorithm based on the alternating direction method of multipliers (ADMM) which enables multiple agents to learn the kernel hyper-parameters collaboratively. The doubly distributed learning algorithm is shown to be effective in reducing the overall computational complexity while preserving data privacy during the learning process. Experiments on various one-dimensional and multidimensional data sets demonstrate that the proposed kernel design yields superior training and prediction performance compared to its competitors.
2021
-
Demystifying model averaging for communication-efficient federated matrix factorization
Shuai Wang, Richard Cornelius Suwandi, Tsung-Hui Chang46th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021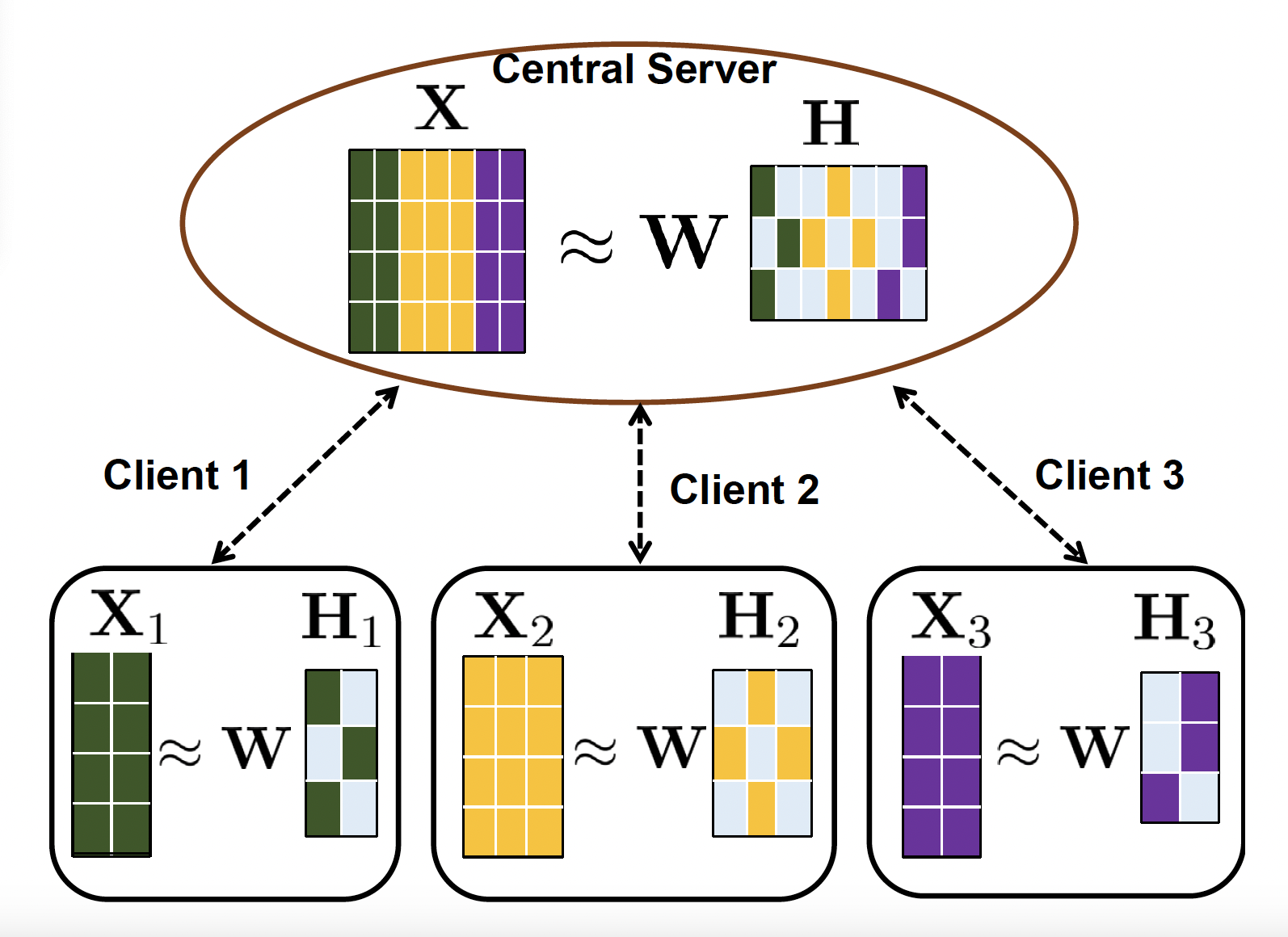
Abstract
Federated learning (FL) is encountered with the challenge of training a model in massive and heterogeneous networks. Model averaging (MA) has become a popular FL paradigm where parallel (stochastic) gradient descent (GD) is run on a small sampled subset of clients multiple times before uploading the local models to a server for averaging, which has been proven effective in reducing the communication cost for achieving a good model. However, MA has not been considered for the important matrix factorization (MF) model, which has vast signal processing and machine learning applications. In this paper, we investigate the federated MF problem and propose a new MA based algorithm, named FedMAvg, by judiciously combining the alternating minimization technique and MA. Through analysis, we show that gradually decreasing the number of local GD and only allowing partial clients to communicate with the server can greatly reduce the communication cost, especially in heterogeneous networks with non-i.i.d. data. Experimental results by applying FedMAvg to data clustering and item recommendation tasks demonstrate its efficacy in terms of both task performance and communication efficiency.