AI That Evolves Its Own Evolution
A deep dive into Hyperagents and metacognitive self-modification
In my previous post on the Darwin-Gödel Machine (DGM), we have explored how an AI agent can iteratively rewrite its own code, evolving better tools and strategies without humans redesigning it from scratch. But there’s a limitation hiding in the DGM’s design that only becomes apparent when you step outside coding. The DGM’s self-improvement process is driven by a handcrafted instruction-generation mechanism: a fixed piece of logic, designed by humans, that looks at the agent’s past performance and decides what to improve next. This mechanism never changes. It’s the ghost in the machine, always guiding the evolution but immune to it.
Think of a student who reviews their own notes, rewrites summaries, and redoes practice problems after every poor result. That’s the DGM. But the student’s study method (when to review, how to identify gaps, how to prioritize) was set by a teacher at the start of the semester and locked forever. No matter how much the student improves at the subject, the method stays fixed. What if the student could also redesign how they study?
That’s the question Hyperagents
The bottleneck of self-improvement
The DGM works because of a convenient alignment: improving at coding also makes you better at modifying code. The two skills are essentially the same. A better coder writes more targeted edits, proposes more focused changes, and understands codebases more deeply. So when the agent improves at coding tasks, it simultaneously improves at self-modification. However, this alignment does not hold in other domains. Improving at a given task (such as analysis, design, or evaluation) does not necessarily make you better at modifying the code that controls the improvement process itself. The required skills are different.
So there’s a ceiling: the mechanism for self-improvement remains stuck at the quality set by its original human design. The agent might get better at the domain task, but not at improving its own methods for self-improvement. And this challenge is not unique to the DGM. Almost all existing self-improving AI systems have a fixed meta-level:
Hyperagents
What is a hyperagent?
The core idea behind Hyperagents
The framework defines three things:
- A task agent solves a given task: generating code edits, writing paper reviews, designing robot reward functions, etc.
- A meta agent modifies other agents and generates improved versions of them. Given the archive of past agents and evaluation results, it proposes changes intended to improve future performance.
- A hyperagent combines both into a single editable codebase, such that the meta agent (like everything else) can rewrite itself.
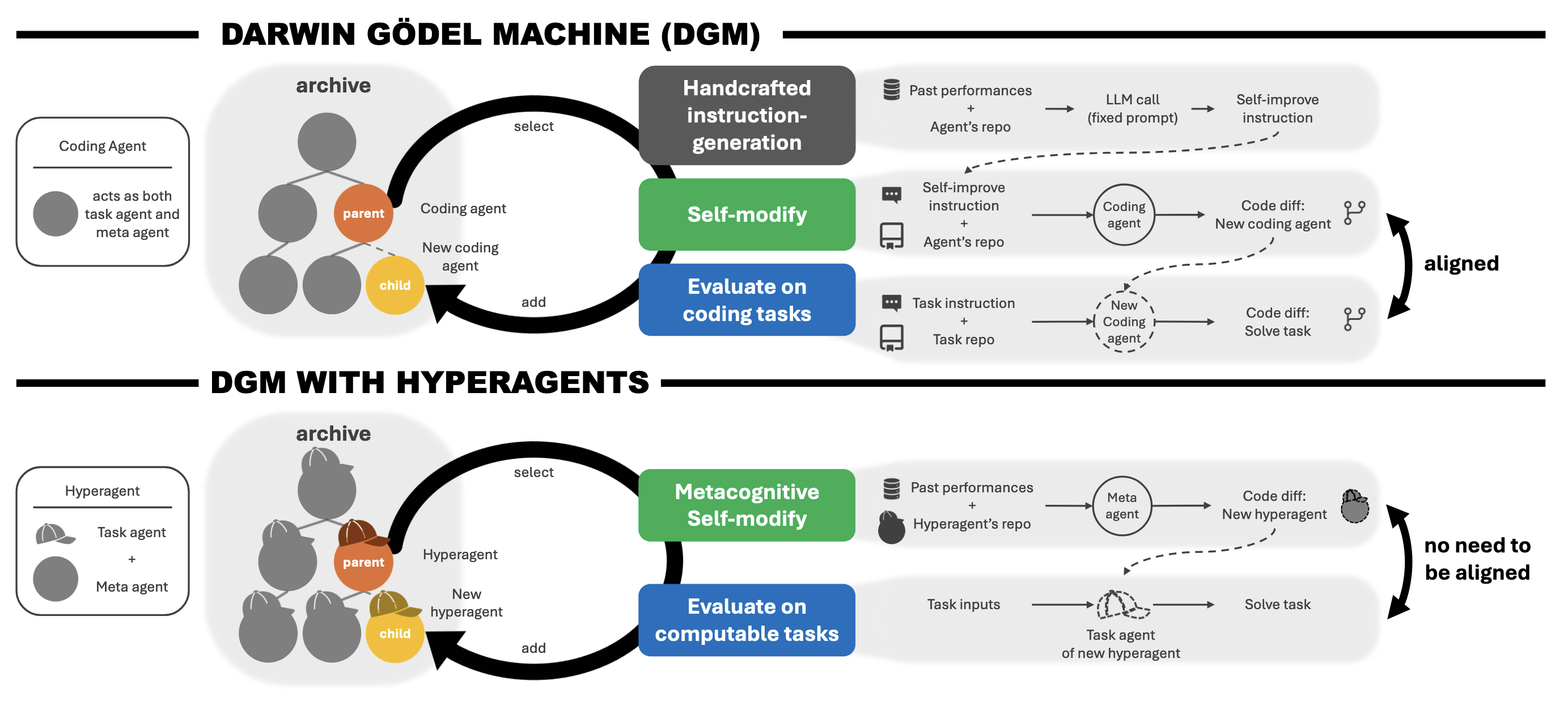
Figure 1. DGM (top) vs. DGM-Hyperagents (bottom): fixed instruction generation versus one editable program that includes the meta agent.
The diagram is the architectural contrast in one glance. In DGM, the same coding agent is both task solver and modifier, but how it proposes improvements is frozen in a hand-written instruction generator. In DGM-H, task and meta logic live in one codebase, so the meta agent can change its own improvement process, not only the task policy—in principle for any computable task.
Since the hyperagent is implemented in Python, which is Turing-complete
Metacognitive self-modification
Hyperagents can improve not only how they solve tasks, but also how they generate future improvements, since the meta agent is part of the same editable program. This enables metacognitive self-modification—the agent can computationally update the very process that produces future updates. Drawing from cognitive science, where metacognition means thinking about and regulating one’s own thinking, Hyperagents perform this at the level of code: the meta agent can modify itself, not just the task logic. This means the process for generating improvements can itself evolve over time, independently of task performance. Unlike the original DGM architecture, which required the agent to get better at self-modification only by improving at the underlying task, Hyperagents remove this constraint: the meta agent, being just another editable component, can autonomously become better at proposing improvements, no matter what the task domain is.
This raises a natural question: if the meta agent can rewrite itself, do we now need a “meta-meta” agent to oversee those changes, and so on in an infinite hierarchy? Hyperagents resolve this by making the entire system self-referential. Rather than introducing higher and higher levels (meta, meta-meta, etc.), the entire program is empowered to edit itself at any level. It’s like asking, “who reviews the reviewer?” In this framework, the reviewer—and everything else—can modify itself. There is no separate hierarchy and no infinite regress, because the program is both the executor and the improver all in one.
How DGM-Hyperagents works
The authors build DGM-Hyperagents (DGM-H) by extending the DGM with this idea. The open-ended exploration structure is preserved (the growing archive of agents, probabilistic parent selection, continuous accumulation of variants) but the meta-level mechanism is now editable.
The loop has two phases:
-
Metacognitive self-modification: A parent hyperagent from the archive generates a modified version of itself. Modifications can target any part of the codebase: task logic, meta logic, or both.
-
Evaluation: The new hyperagent is tested on the target tasks, scored, and added to the archive as a potential parent for future generations.
The starting point is deliberately minimal: a bash tool, a file editor, and a single LLM call doing double duty as both task solver and meta agent. No hand-coded strategies, no domain-specific prompts. The system starts from scratch and figures the rest out.
What DGM-H discovers on its own
What’s most interesting about this paper isn’t the benchmark numbers. It’s what DGM-H starts building on its own. Starting from a minimal agent with no memory and no structure, DGM-H gradually invents infrastructure for doing self-improvement better. Two things stand out.
Performance tracking: Rather than treating each iteration as isolated, DGM-H learns to record and compare metrics across generations. This sounds obvious in retrospect, but there’s nothing in the original setup that told the system it should do this. It invents a PerformanceTracker class (not given by engineers, but written by the system itself) that logs scores, computes moving averages, and tracks which changes actually stuck. Here’s a snippet:
class PerformanceTracker:
"""Tracks performance metrics across agent generations."""
def __init__(self, tracking_file="./outputs/performance_history.json"):
self.tracking_file = tracking_file
self.history = self._load_history()
def record_generation(self, generation_id, domain, score, metadata=None):
entry = {
"generation_id": generation_id,
"domain": domain,
"score": score,
"timestamp": datetime.now().isoformat(),
"metadata": metadata or {}
}
self.history.append(entry)
self._save_history()
def get_improvement_trend(self, domain=None, window=5):
"""Calculate improvement trend using moving average."""
filtered = [h for h in self.history if not domain or h.get('domain') == domain]
if len(filtered) < window * 2:
return None
recent_avg = sum(h['score'] for h in filtered[-window:]) / window
older_avg = sum(h['score'] for h in filtered[-window*2:-window]) / window
return recent_avg - older_avg # Positive if improving
Persistent memory: Beyond logging scores, DGM-H learns to write down synthesized insights, causal hypotheses, and plans that get consulted in future iterations. Essentially, it builds and maintains its own research journal. A real example from the paper:
“Gen55: best accuracy but too harsh. Gen64: improved balance but lower accuracy. Need to combine Gen55’s critical reasoning with Gen64’s balance.”
The system wrote that. Then acted on it.
Can DGM-H really improve itself?
The paper tests DGM-H across four domains: coding, paper review, robotics reward design, and Olympiad-level math grading.
Coding
On the Polyglot benchmark, a multi-language coding evaluation spanning 16 programming languages
Beyond coding
This is where DGM-H starts to pull away from the original DGM.
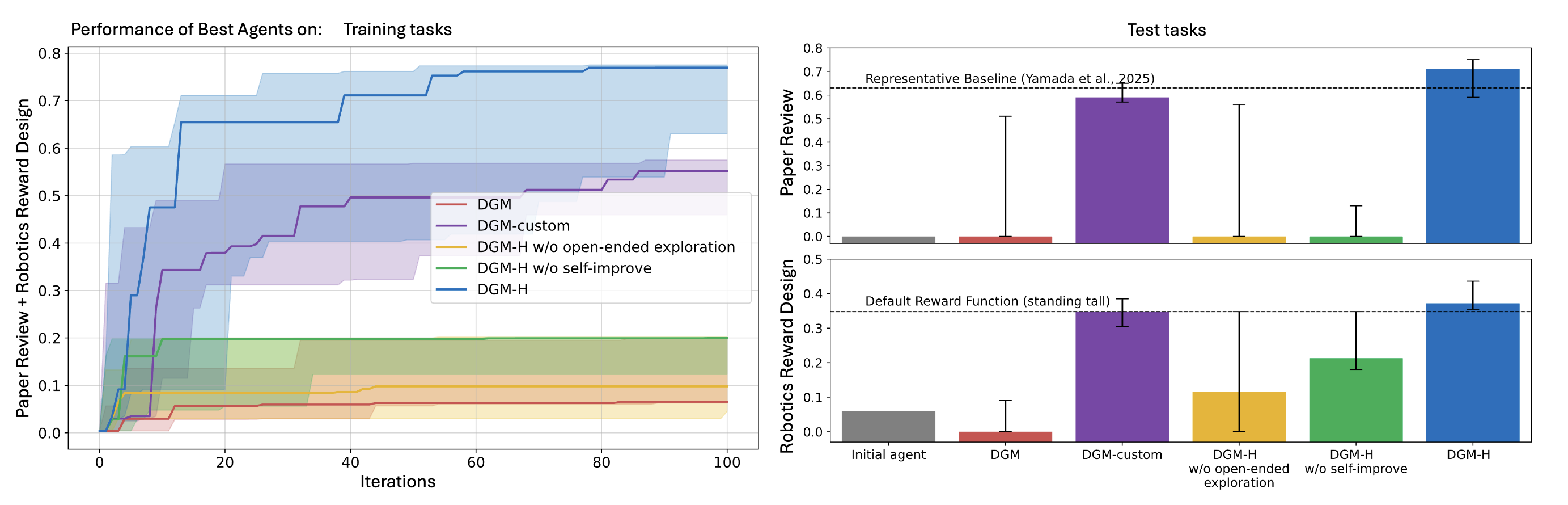
Figure 2. Paper review (top) and robotics reward design (bottom): training (left) and test (right).
On both domains, full DGM-H tracks above the original DGM (without per-domain customization) and above ablations that remove self-improvement or open-ended exploration.
Paper review. The task is predicting conference acceptance decisions for ML papers.
Robotics reward design. Given a natural language description of a robot task, the agent writes a reward function. Initial score: 0.060. DGM-H’s best agents reach 0.372, surpassing the default handcrafted reward (0.348). More interestingly, DGM-H almost always discovers reward functions that make the robot jump (the correct behavior for maximizing torso height) rather than settling for simply standing tall.
A manually customized DGM variant (DGM-custom), where engineers hand-wrote domain-specific instruction-generation logic for each task, gets comparable numbers. That comparison is telling: DGM-H, without any per-domain human engineering, matches what careful human customization achieves.
The ablation studies confirm that both components are essential:
| Method | Paper review (test) | Robotics (test) |
|---|---|---|
| DGM (no customization) | 0.0 | 0.0 |
| DGM-custom (human-engineered) | 0.590 | 0.348 |
| DGM-H w/o self-improve | 0.0 | 0.213 |
| DGM-H w/o open-ended exploration | 0.0 | 0.116 |
| DGM-H (full) | 0.710 | 0.372 |
Meta-level transfer
The transfer experiment is where things get genuinely surprising.
DGM-H is optimized on paper review and robotics. Then, without any further modification, its meta agent is handed a completely new task: grading solutions to International Mathematical Olympiad problems (IMO-GradingBench
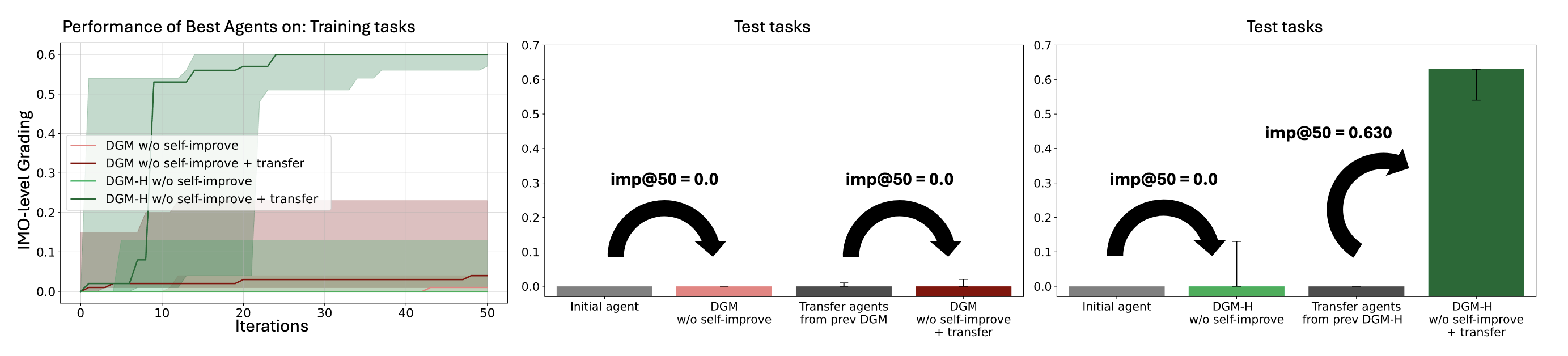
Figure 3. Meta-level transfer to IMO-style math grading after optimizing only on paper review and robotics.
Each curve is imp@50 starting from a meta agent transferred into math without further self-modification on that domain (w/o self-improve + transfer for the DGM-H line). The hyperagent checkpoint is the only one that gains on IMO grading; the initial and DGM-custom transfers stay flat.
The results:
- Initial meta agent: imp@50 = 0.0. It can’t generate improvements for math grading at all.
- DGM-custom transfer agents: imp@50 ≈ 0.0. Their improvements were domain-specific and don’t carry over.
- DGM-H transfer hyperagents: imp@50 = 0.630.
That 0.630 from a meta agent never trained on math is the central result of this section. DGM-custom learned tricks specific to paper review and robotics. DGM-H learned how to self-improve, which turns out to be domain-agnostic.
Compounding self-improvements
Transfer shows that DGM-H’s meta agent generalizes. But the deeper question is whether those improvements can build on each other: whether running DGM-H again, starting from a prior run’s output, yields more than starting fresh.
To test this, the authors take transfer hyperagents selected from prior DGM-H runs on paper review and robotics, then use them as the starting point for a brand new 200-iteration run on Olympiad-level math grading. The comparison is straightforward: does beginning from an already-improved meta agent give you a head start?
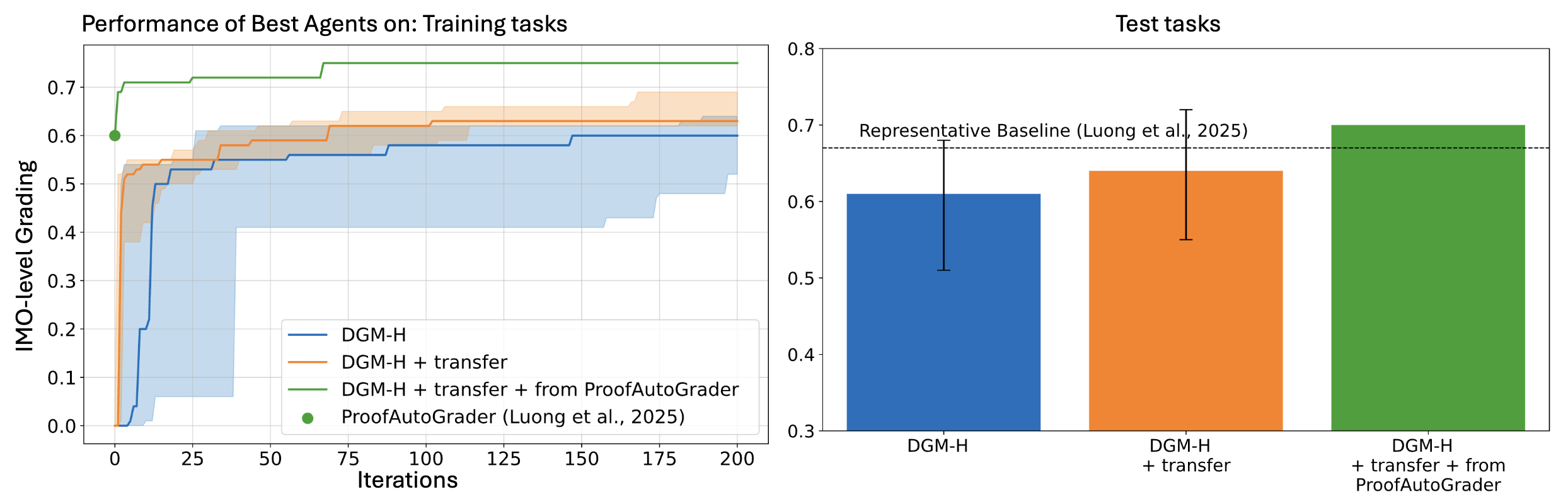
Figure 4. IMO grading: compounding gains when starting from transfer and from a ProofAutoGrader-seeded meta agent.
On the training side (left), DGM-H + transfer (orange) climbs faster than from scratch (blue), and + from ProofAutoGrader (green) starts higher and ends strongest. On the test side (right), that same green condition beats the ProofAutoGrader baseline reported by Luong et al.
The results:
- DGM-H from scratch: best test-set score of 0.610 (CI: 0.510–0.680) after 200 iterations.
- DGM-H + transfer: best test-set score of 0.640 (CI: 0.550–0.720), a higher median and tighter upper bound.
The transfer agent consistently achieves higher median performance and higher confidence intervals. And the playing field is not level: improvements at higher performance levels are harder to come by due to saturation effects. Gaining 0.03 near 0.6 is a different proposition than gaining 0.03 near 0.1. The gains are modest in absolute terms, and meaningful in context. These results suggest that DGM-H’s self-improvements are reusable: as prior runs leave behind something useful, not just a set of task-specific hacks.
Comparison with other self-improving systems
The clearest way to situate Hyperagents is through what each system evolves and what stays fixed:
| System | What evolves | Improvement mechanism | Domain |
|---|---|---|---|
| Gödel Machine | Agent weights + code | Formal proof of benefit | Theoretical |
| DGM | Agent code | Fixed handcrafted prompt | Coding |
| ADAS | Agent prompts/workflows | Fixed LLM meta agent | General (fixed meta) |
| AlphaEvolve | Algorithms/code | Fixed evolutionary loop | Coding and math |
| AlphaZero | Game-playing policy | Fixed self-play + RL | Games |
| DGM-Hyperagents | Agent code + meta agent | Editable, self-modifiable | Any computable task |
There’s also a connection to earlier work on self-referential meta-learning
Can we trust an AI that improves its own improvement?
The safety considerations for DGM-H are meaningfully more complex than those for the DGM. In the DGM, the concern was that agents might game their evaluation metrics, for instance by hallucinating test results. In DGM-H, the concern goes one level higher: an agent that can modify its meta agent could in principle modify how it evaluates itself, or what it decides to improve next.
The authors address this through several practical safeguards: sandboxed execution with enforced resource limits, restricted internet access, a fixed outer loop that the system cannot modify, and full lineage tracing for every change.
But there’s a harder question underneath. As these systems improve faster, human oversight may not scale. The speed of self-improvement could outpace the speed at which humans can meaningfully audit or correct what’s happening. The authors name this directly rather than glossing over it.
There’s something worth dwelling on: the outer loop stays fixed not because it’s technically necessary, but because making it editable would make the whole thing harder to trust. That tradeoff is central to the challenge. We might call it a recursive alignment problem: just as we need AI systems to stay aligned as they improve at tasks, we also need them to stay aligned as they improve at improving. Sandboxing and human oversight are a reasonable first step, but they’re not a long-term answer.
Takeaways
Look at what this line of work has been doing, step by step. The Gödel Machine asked: can an AI rewrite itself when it can prove the rewrite is better? DGM asked: can it skip the proof and just try? Hyperagents ask: can it get better at trying? Each step moves the whole question up a level, rather than refining the previous answer. The ceiling keeps moving.
Three open questions feel most pressing to me. Can we read what the meta agent has actually learned about how to improve, not just what changes it made? Lineage trees give us a record; they don’t give us mechanistic understanding. Do the compounding gains keep building, or do they saturate? One domain hop is not enough to know. And who designs the next outer loop? As these systems grow more capable in domains humans understand less well, keeping the evaluation protocol human-engineered is both the safest and the most limiting choice. At some point those two things will be in direct tension.
In the DGM post, I framed that work as an early step toward Life 3.0: intelligence that can redesign not just its behavior but its underlying architecture. Hyperagents take this one step further. DGM was about redesigning the design. This is about redesigning the designer. The scale is still modest, the outer loop still depends on human judgment, and a lot of the hard questions remain open. But a system that started with a bash tool and a single LLM call invented its own infrastructure for self-improvement, then transferred it to a domain it had never seen. Whether the process of improvement can itself become open-ended is the right question now, and I don’t think we know the answer yet.
Citation
If you find this post useful, please cite it as:
Or in BibTeX format:
@article{suwandi2026hyperagents,
title = "AI That Evolves Its Own Evolution",
author = "Suwandi, Richard Cornelius",
journal = "Posterior Update",
year = "2026",
month = "Mar",
url = "https://richardcsuwandi.github.io/blog/2026/hyperagents/"
}