The Science of Intelligent Exploration
Why we need to re-center exploration in AI
One of the most thought-provoking moments for me at ICML 2025 didn’t come from a new architecture or a scaling law. It emerged from a simple, unsettling question: What happens when AI stops exploring? Recent breakthroughs in AI—especially in LLMs—have been fueled not by curiosity, but by curation. By training on vast amounts of human-generated data, models like LLMs bypass the messy, uncertain process of active exploration. Instead, they absorb a pre-digested version of our collective knowledge, effectively “pre-exploring” the world through the lens of what’s already been written

Figure 1. List of research questions at the EXAIT Workshop at ICML 2025.
Embracing the unexpected
Let’s start with a counterintuitive concept that flips traditional optimization on its head: novelty search
where $k$ is the number of nearest neighbors in the archive. This encourages agents to venture into unexplored regions of behavior space, creating a diverse portfolio of solutions.
In a classic maze experiment
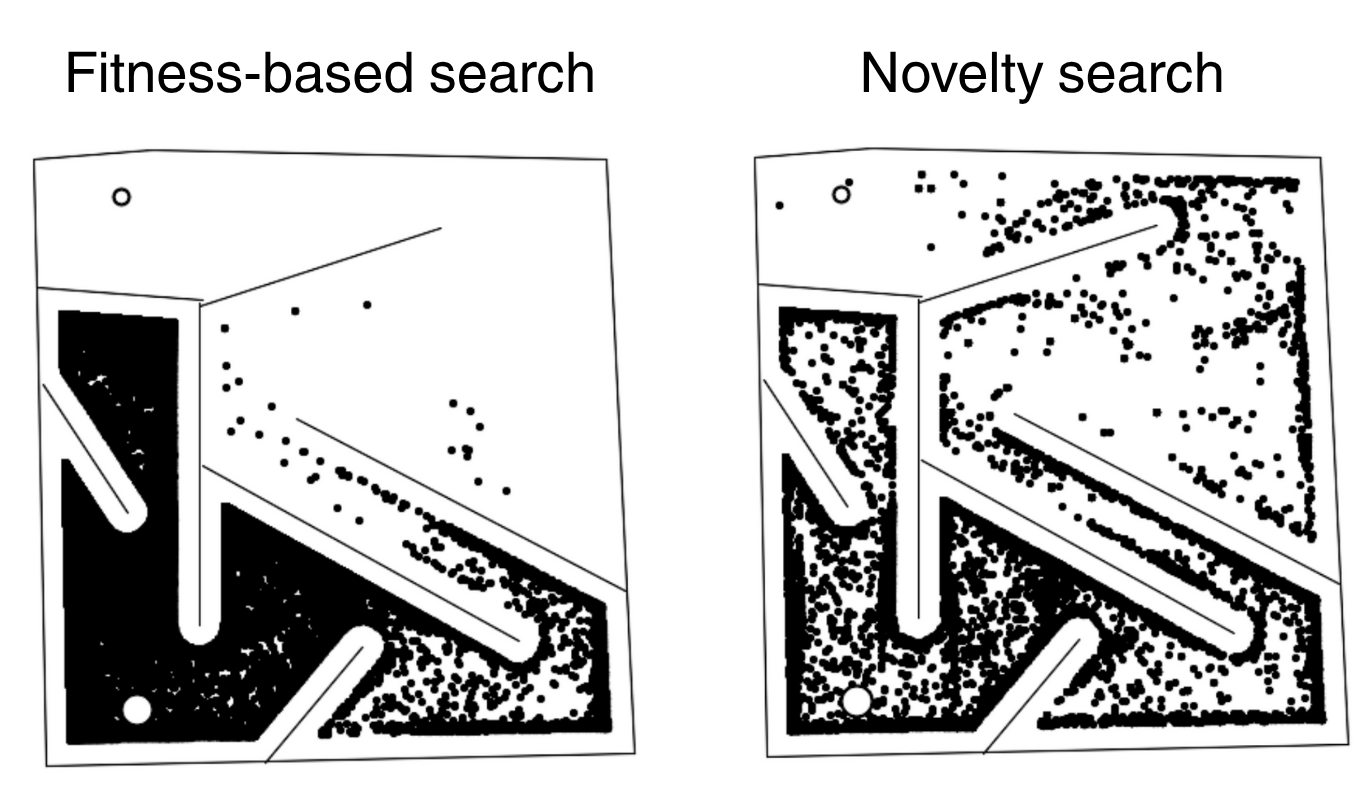
Figure 1. Novelty search vs fitness-based search in a maze.
The stepping stones to success often look nothing like the goal itself. For example, the path from abacuses to laptops involved seemingly unrelated innovations like electricity and vacuum tubes. An interesting experiment that demonstrates this is Picbreeder, a platform where users evolve images through novelty search. A user aiming for a car might end up with a spaceship-like form that, through further exploration, morphs into a car. The lesson? Ignoring the objective can sometimes get you there faster.
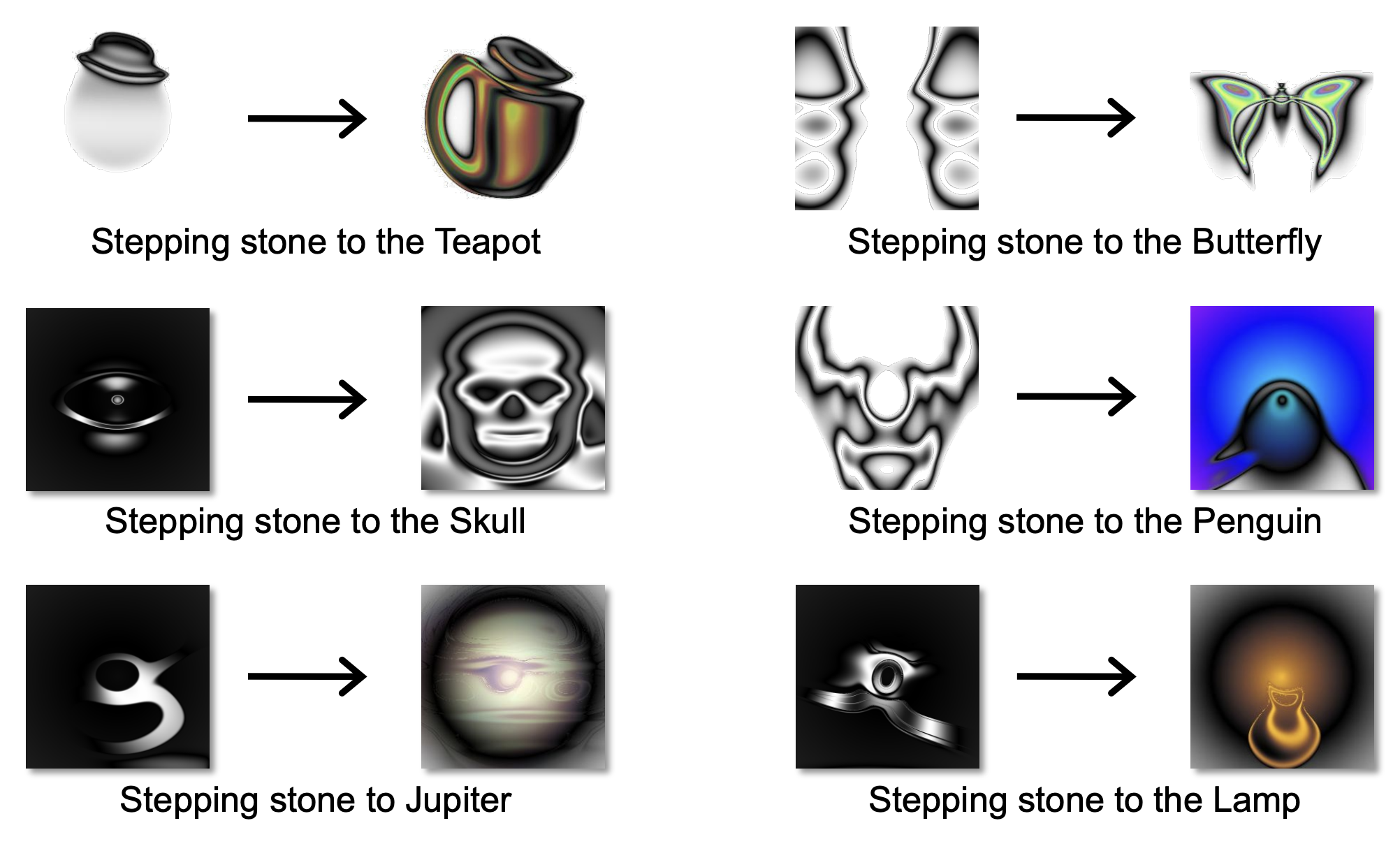
Figure 2. What Picbreeder shows: The stepping stones almost never resemble the final product! You can only find things by not looking for them.
But novelty alone isn’t enough. What if we could balance exploration with quality? That’s where quality diversity comes in.
Beyond a single solution
While novelty search embraces exploration, quality diversity (QD) takes it a step further by seeking diverse solutions that are also high-performing. Instead of finding a single “best” solution, QD algorithms like MAP-Elite
- Initialize: Create an empty map with predefined behavioral dimensions
- Generate: Create new solutions through mutation or crossover
- Evaluate: Measure both performance (fitness) and behavior characteristics
- Place: Assign each solution to its corresponding map cell
- Select: Keep only the best-performing solution in each cell
- Repeat: Continue until the map is sufficiently filled
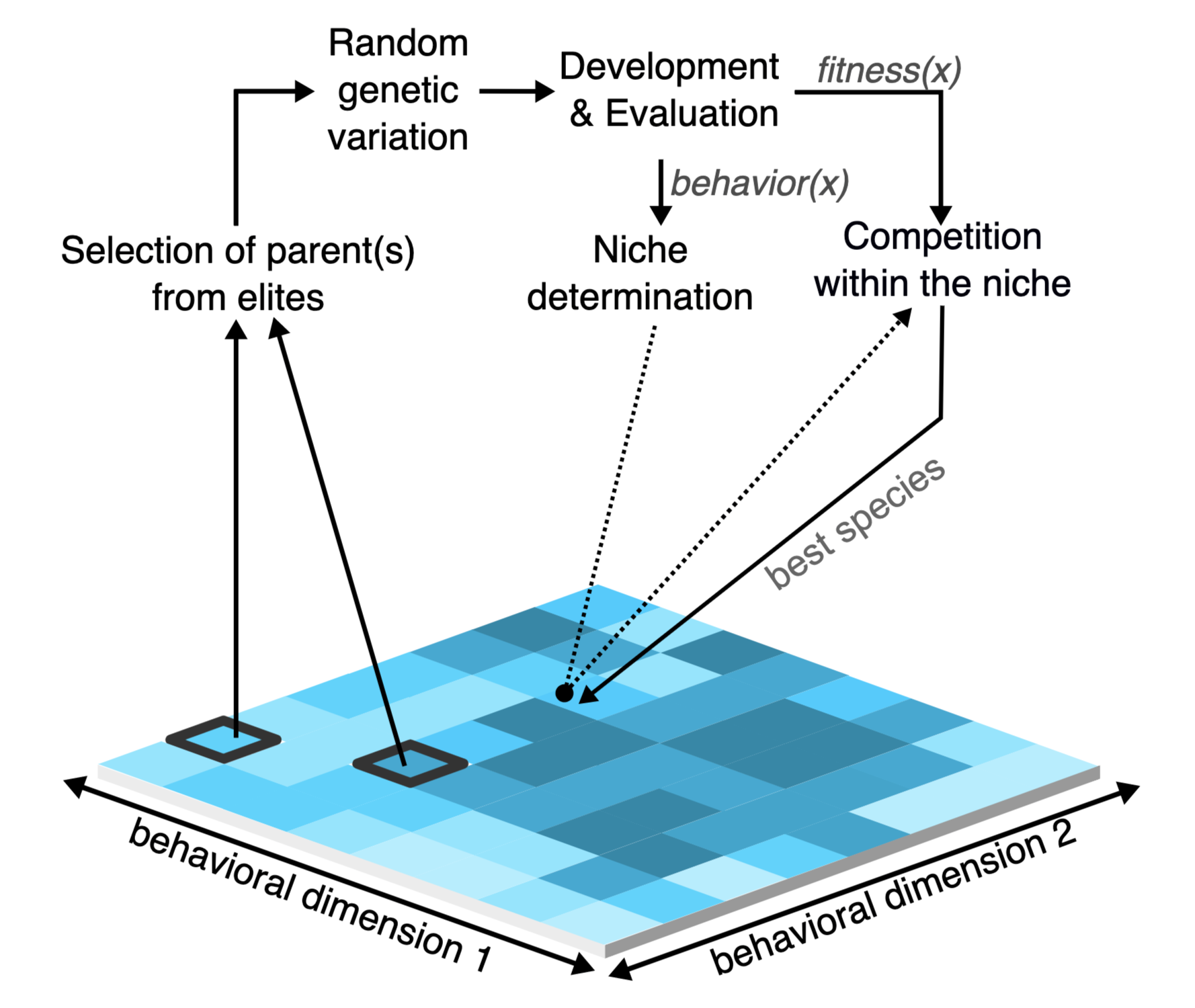
Figure 3. MAP-Elites in action.
The result is a comprehensive “atlas” of high-quality solutions across the entire behavioral landscape
One of QD’s most striking successes came in robotics, where MAP-Elites generated diverse walking gaits for six-legged robots
Another notable QD algorithm is Go-Explore
Yet, QD still operates within a finite, predefined domain. What if we could go beyond finding what’s possible and start inventing new possibilities? This brings us to open-ended algorithms.
Towards endless innovation
Open-ended algorithms aim to mimic the boundless creativity of natural evolution or human culture. Unlike traditional algorithms that converge on a solution, open-ended systems diverge, endlessly generating new challenges and solving them. The goal? To keep learning and innovating, no matter how much time or compute is available.
Interested readers can refer to my previous post for a comprehensive overview of open-endedness.
A prime example of modern open-endedness is the Paired Open-Ended Trailblazer (POET)
- Environment Generation: Create new training environments by mutating existing ones (e.g., changing terrain difficulty, adding obstacles)
- Agent Training: Each environment trains its own population of agents using standard RL
- Transfer Evaluation: Regularly test agents on environments other than their native ones
- Selective Transfer: Move high-performing agents to environments where they can contribute
- Environment Selection: Preserve environments that are “minimal criteria” (not too easy, not impossibly hard)
The most interesting part lies in the co-evolutionary arms race: as agents get better, environments become more challenging; as environments become harder, agents must develop more sophisticated strategies. Open-endedness is about more than solving problems—it’s about creating a system that generates its own problems and learns from them. This brings us to the next frontier: AI-generating algorithms (AI-GAs)
A path to general intelligence
In his 2019 paper, Jeff Clune proposed AI-GAs as a path to AGI, built on three pillars:
- Meta-learning architectures: Automatically designing neural network structures tailored to specific tasks.
- Meta-learning learning algorithms: Evolving the rules of learning itself, like how gradients are updated.
- Generating effective learning environments: Creating diverse, challenging environments to train AI systems.
Meta-learning architectures
Traditional neural architecture search (NAS) focuses on finding good architectures for specific datasets. AI-GA approaches go further by evolving architectures that can quickly adapt to new tasks. Recent examples include:
- ENAS (Efficient neural architecture search)
: Uses reinforcement learning to discover architectures, dramatically reducing search time from thousands to single GPU-days. - DARTS (Differentiable architecture search)
: Makes architecture search differentiable, enabling gradient-based optimization of network topology. - AutoML-Zero
: Evolves entire machine learning algorithms from scratch, starting with mathematical primitives and building up to complex architectures and optimizers.
Instead of hand-designing architectures, let evolution discover designs optimized for specific problem classes or computational constraints.
Meta-learning learning algorithms
This involves evolving not just what the network learns, but how it learns. Examples include:
- Learned optimizers
: Instead of using SGD or Adam, train neural networks to optimize other neural networks. These “learned optimizers” can adapt their strategy based on the loss landscape. - Meta-learning with gradient descent
: Model-agnostic meta-learning (MAML) trains models to be good at learning new tasks with just a few gradient steps. - Evolutionary strategy for RL
: Replace backpropagation entirely with evolution strategies that can discover entirely new learning rules.
Generating effective learning environments
Traditional AI training has relied on fixed datasets or hand-crafted environments. While this approach has enabled progress, it is fundamentally limited: hand-coding environments is brittle, and it is notoriously difficult to define what makes a task “interesting” or “useful” for learning. Early attempts to automate environment generation often used simple heuristics, such as:
- Goldilocks Principle: Environments should be neither too easy (boring) nor too hard (impossible)
- Learning progress: Prioritize environments where agents are improving fastest
- Behavioral diversity: Generate environments that elicit different behaviors
But these approaches often miss the nuanced understanding of what makes a problem genuinely interesting or valuable for developing intelligence. A recent example is OMNI
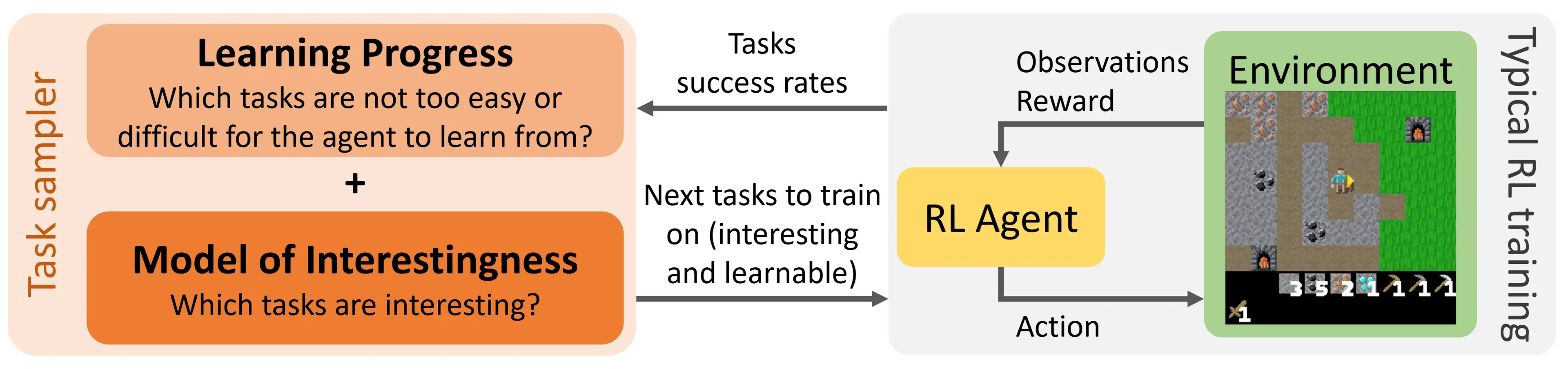
Figure 4. OMNI combines a learning progress auto-curriculum and a model of interestingness, to train an RL agent in a task-conditioned manner.
Despite this, OMNI is still fundamentally limited by the scope of their environment generators—typically confined to a narrow, predefined distribution of tasks. This limitation restricts the true potential of open-ended learning, which aspires to create agents capable of tackling an unbounded variety of challenges. On the other hand, the grand vision of open-endedness in AI is to continuously generate and solve increasingly complex and diverse tasks, much like the creative explosion seen in biological evolution and human culture Achieving this would require algorithms that can operate within a truly vast—ideally infinite—space of possible environments. A key concept here is Darwin Completeness.
Darwin Completeness is the ability of an environment generator to, in principle, create any possible learning environment. This means not just tweaking parameters within a fixed simulator, but being able to generate entirely new worlds, rules, and reward structures.
OMNI-EPIC
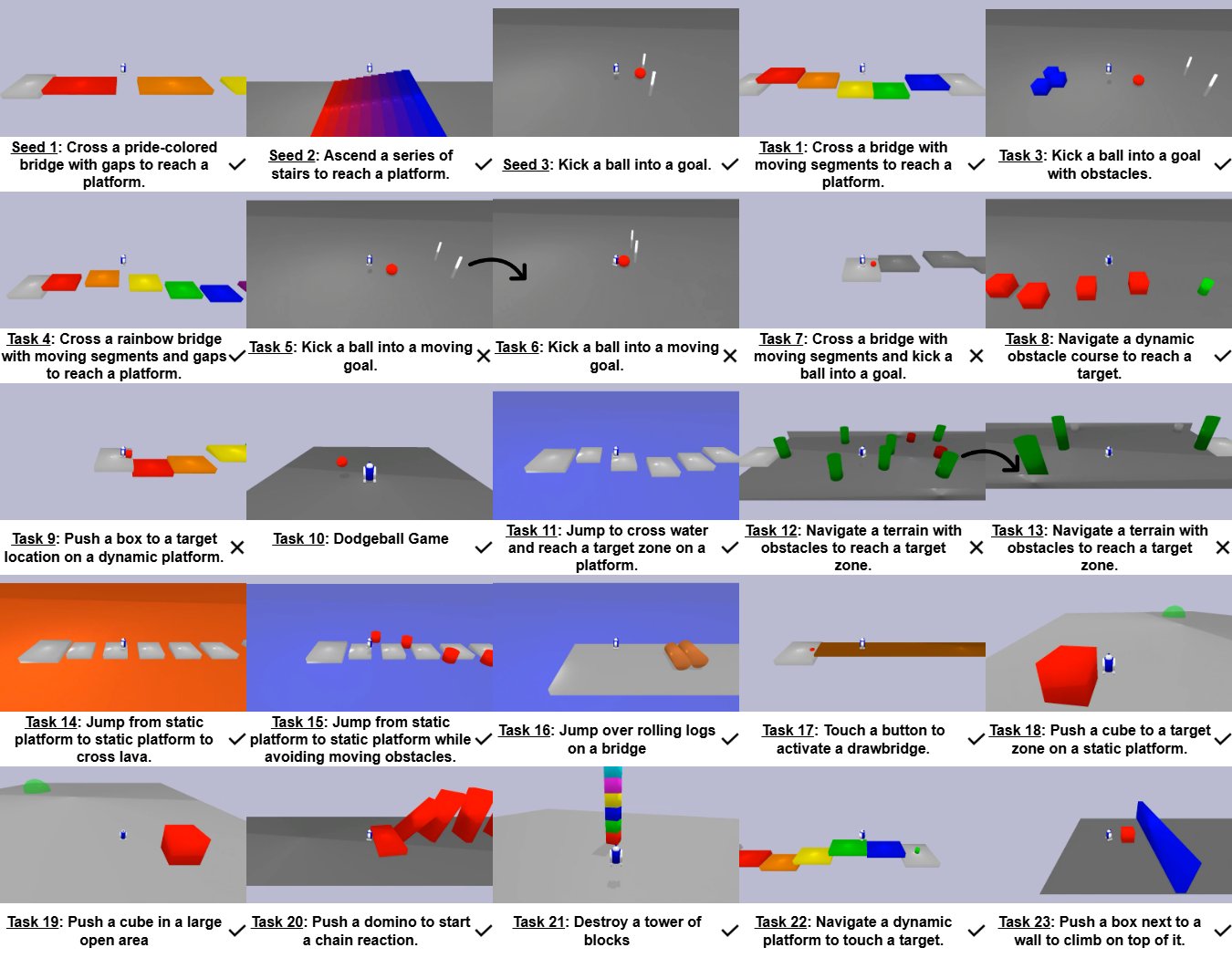
Figure 5. Examples of environments generated by OMNI-EPIC. All of these are generated using only 3 initial seeds!
Another notable advance in this direction is Genie
Figure 6. From concept art and drawings to fully interactive environments.
To showcase the power of Genie 2, DeepMind introduced SIMA
Figure 7. SIMA can follow natural language instructions in an unseen environment. The environment is generated via a single prompt image using Imagen and turned into a 3D world by Genie 2.
The combination of a powerful environment generator and an agent forms a virtuous cycle: as the environment generator creates new worlds, the agent must adapt and learn, and their progress can be used to further refine both the agent and the environment generation process.
Exploration is the future
One way to understand the urgency of re-centering exploration in AI is through the lens of the emerging Software² paradigm. While traditional deep learning (Software 2.0) focuses on learning from vast, static datasets, Software² envisions a new generation of AI systems that actively seek out and generate their own training data. This shift—from passively absorbing curated data to actively exploring and producing new, informative experiences—places exploration at the heart of progress. In this view, the ability of an AI to decide what data to learn from, and to continually expand its own learning environment, becomes a critical driver of generality and innovation. As we move toward more open-ended and self-improving AI, the science of exploration is poised to become the central engine of advancement.
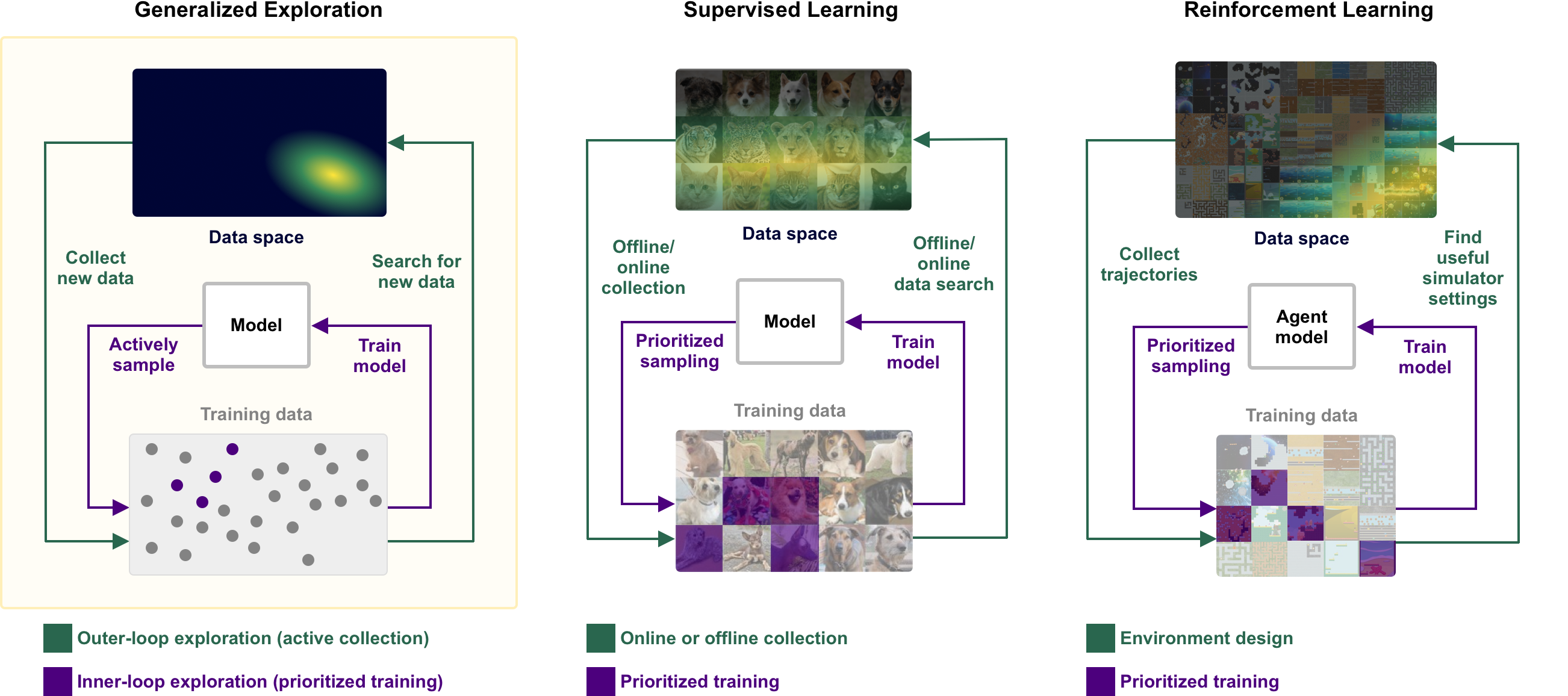
Figure 8. Software² rests on a form of generalized exploration for active data collection. Unlike existing notions of exploration in RL and SL (where it takes the form of active learning), generalized exploration seeks the most informative samples from the full data space.
Closely related is the vision articulated in The Era of Experience, which argues that the next leap in AI will come not from scaling up static data, but from enabling agents to learn through rich, interactive experiences. In this new era, AI systems will continually generate, seek out, and learn from novel experiences—mirroring the way humans and animals learn by engaging with the world. Exploration, therefore, is not just a technical detail, but the foundation of a new paradigm where experience itself becomes the primary driver of intelligence.
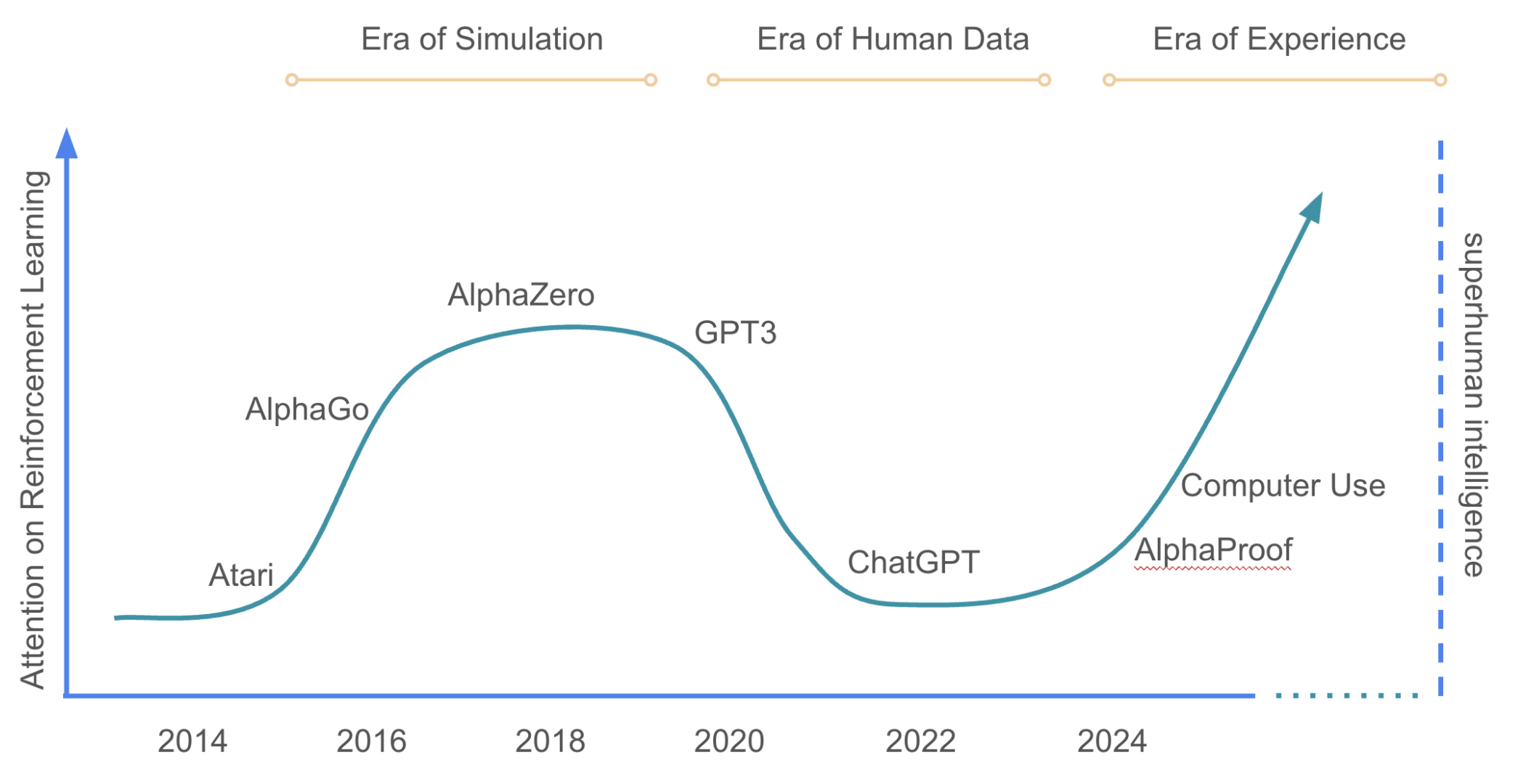
Figure 9. We are currently transitioning from the Era of Data to the Era of Experience.
Takeaways
Intelligent exploration lies at the heart of discovery, creativity, and adaptation—across science, innovation, and AI. We have just seen that breakthroughs rarely come from following a single, well-trodden path. Instead, they emerge from venturing into the unknown, embracing diversity, and allowing for serendipity and surprise. As AI evolves, the most capable and resilient systems will be those that do more than optimize known patterns—they will actively seek the adjacent possible, generate novel experiences, and expand the frontiers of knowledge. To build truly general and self-improving systems, we must elevate exploration to a first-class principle in AI design. The future belongs to those who explore. Let us design AI that does the same.
Citation
If you find this post useful, please cite it as:
Or in BibTeX format:
@article{suwandi2025explorationai,
title = "The Science of Intelligent Exploration",
author = "Suwandi, Richard Cornelius",
journal = "Posterior Update",
year = "2025",
month = "Jul",
url = "https://richardcsuwandi.github.io/blog/2025/exploration-in-ai/"
}