The Dream Machines
How AI is learning to simulate our physical world
A young girl sits, not in front of a screen, but within a world of her own making. With a thought, she conjures a cyberpunk metropolis—a sprawling cityscape alive with neon lights and towering skyscrapers. The air is thick with the scent of rain as crowds of people navigate elevated walkways under umbrellas, their reflections shimmering on wet surfaces below. She slips into the body of a luminous koi, diving through this immersive world from an aquatic perspective. The city comes alive around her, its neon glow reflecting off her scales as she swims past towering buildings and floating advertisements. She is not just playing a game; she is living in a dream—a world that responds to her every whim, a world that learns and grows with her. This is not a scene from a distant science fiction novel. This is the future that “dream machines” like Genie 3 are beginning to build, one pixel at a time.
Figure 1. A sample world generated by Genie 3. Clip from @apples_jimmy and @MattMcGill_ on X.
These models aren’t just tools for creating games. They are engines of experience, simulators of reality, and perhaps, the key to unlocking the next stage of artificial general intelligence (AGI). But what does it mean when the line between our dreams and our digital realities begins to blur? In this post, we will explore how foundation world models like Genie are reshaping our digital world and where they might take us next.
The birth of dream machines
For years, AI has dazzled us with its creative abilities, from writing eloquent stories and generating stunning artwork to producing convincing video. But now, with models like Genie, we are witnessing a new kind of breakthrough. Rather than simply creating content to be observed, these models generate worlds that can be explored and shaped in real time. For example, we can now generate a 3D world from a single image, and even interact with it in real time. This shift marks the beginning of what NVIDIA’s Jensen Huang envisioned—a future where every single pixel will be generated, not rendered.
The path to interactive world generation began with a crucial realization: the most sophisticated video generation models were inadvertently learning to simulate reality. When OpenAI unveiled Sora
Figure 2. A video generated by Sora using the prompt: “Photorealistic closeup video of two pirate ships battling each other as they sail inside a cup of coffee.”
Google’s Veo 3
Yet for all their sophistication, these systems shared a fundamental limitation that highlighted the next frontier. You could watch their generated worlds, but you couldn’t inhabit them
What is a “world model”?
Before we dive deeper, let’s clarify what we mean by a “world model.”
A world model is a system that can simulate the dynamics of an environment.
In other words, it is a model that is able to predict how actions change states and how the environment evolves over time. Perhaps the best way to understand world models is to consider how humans operate. As Jay Wright Forrester, a pioneer of systems dynamics, observed:
“The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system.”
To understand this better, consider the following intuitive example from
Imagine you’re playing a baseball game. You have mere milliseconds to decide how to swing—less time than it takes for visual signals to travel from eyes to brain. Yet professional players consistently make contact. How? Their brains have developed predictive models that can anticipate where and when the ball will arrive, allowing for subconscious, reflexive responses based on internal simulations of the ball’s trajectory.
AI world models also use similar principles to simulate our physical world. They learn the “rules” not through explicit programming, but by observing countless examples of how things behave. For instance, a world model might discover that water flows downward and around obstacles, objects cast shadows that change with lighting, and characters maintain consistent appearances from different angles.
How to build a world model?
The classic world model
The role of the V component is to take high-dimensional observations and encodes them into compact, meaningful representations
The role of the M component is to learn temporal patterns and predicts future states based on past experience
The role of the C is to map the current compressed state and predicted future to select actions

Figure 3. Overview of a world model architecture showing the interaction between Vision (V), Memory (M), and Controller (C) components
Learning inside dreams
Perhaps the most remarkable capability of world models is to “learn inside dreams”. Instead of learning in the real world, an agent can learn to perform tasks entirely within the simulated environment generated by its own world model. The process works like this:
- The world model observes the real environment and learns its dynamics.
- The controller trains by taking actions in this learned simulation, experiencing consequences and rewards without ever touching the actual environment.
- The trained policy transfers back to reality.
This approach offers several advantages:
-
Accelerated learning: Time moves at computational speed rather than physical speed. For example, a robotic system can experience years of practice in days of compute time, potentially learning from more diverse scenarios than would be possible in a lifetime of real-world operation.
-
Rare event training: Edge cases that might occur once in millions of real-world interactions can be generated on demand in simulation. For example, a rescue robot can train for disaster scenarios that haven’t happened yet.
-
Safety and ethics: Dangerous scenarios—car crashes, medical emergencies, military conflicts—can be simulated without real-world consequences. For example, an autonomous vehicle can experience thousands of potential accidents in simulation, learning to avoid them without endangering anyone.
While traditional simulators rely on people manually programming how things move and interact, including rare or complex situations, world models learn these behaviors by analyzing real-world data, which allows them to capture details that humans might overlook or find too hard to describe.
A whole new world
Building on the foundational insights from world models research, DeepMind’s Genie
How Genie works
Unlike traditional game engines that rely on hand-coded physics and pre-designed assets, or video models that generate fixed sequences, Genie learns to create controllable environments entirely from observing unlabeled internet videos
Converts raw video frames into compressed discrete tokens that capture both spatial and temporal patterns. Rather than processing each frame independently, this component uses a novel spatiotemporal approach that understands how visual elements change over time. It compresses 16×16 pixel patches across multiple frames into discrete tokens
Discovers and learns a discrete action space entirely from observing video transitions, without any action labels. This component observes pairs of consecutive video frames and learns to infer what “action” must have occurred to cause the transition from frame A to frame B.
Generates the next frame tokens given the current state and a chosen latent action
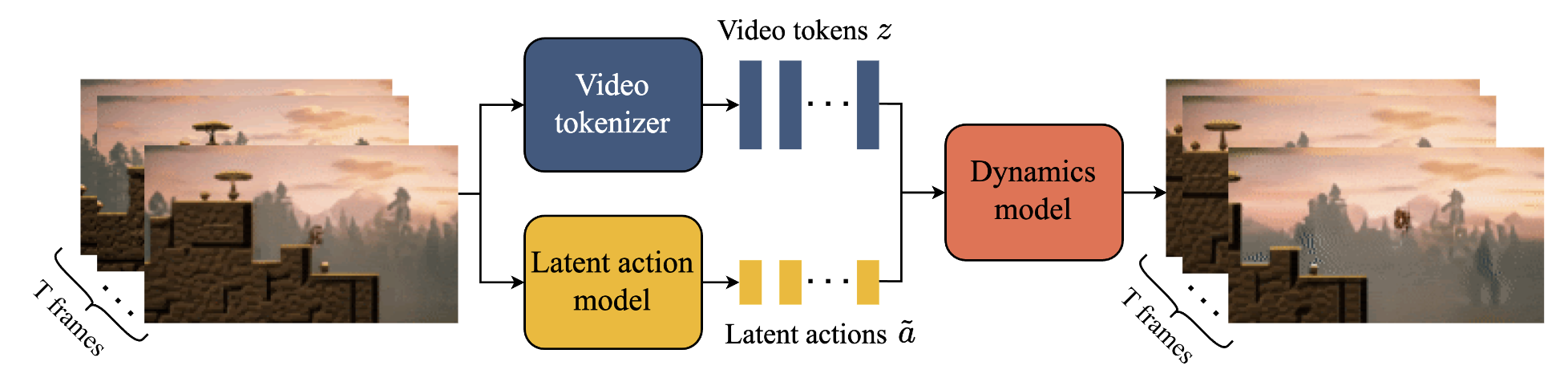
Figure 4. Genie takes in $T$ frames of video as input, tokenizes them into discrete tokens $\mathbf{z}$ via the video tokenizer, and infers the latent actions $\tilde{\mathbf{a}}$ between each frame with the latent action model. Both are then passed to the dynamics model to generate predictions for the next $T$ frames in an iterative manner.
What makes Genie remarkable is how these components learn to work together without explicit supervision. The system watches millions of video transitions and automatically discovers that certain types of changes occur repeatedly—characters moving in different directions, jumping, interacting with objects. It learns to represent these as discrete latent actions. Simultaneously, the dynamics model learns to predict what happens when each type of action is taken in different contexts. It develops an understanding of physics, object interactions, and environmental consistency. All three components are trained together, creating a feedback loop where better action recognition improves dynamics prediction, and better dynamics prediction enables more precise action discovery.
Beyond 2D worlds
The original Genie’s transformation of 2D sprite-based games into interactive, explorable worlds was just the beginning. By late 2024, DeepMind had set its sights on a far more ambitious target: scaling these insights to create fully three-dimensional, photorealistic worlds that could rival modern game engines in visual quality while surpassing them in creative flexibility. Just eight months after the original Genie captured the world’s imagination with its 2D interactive environments, DeepMind unveiled Genie 2
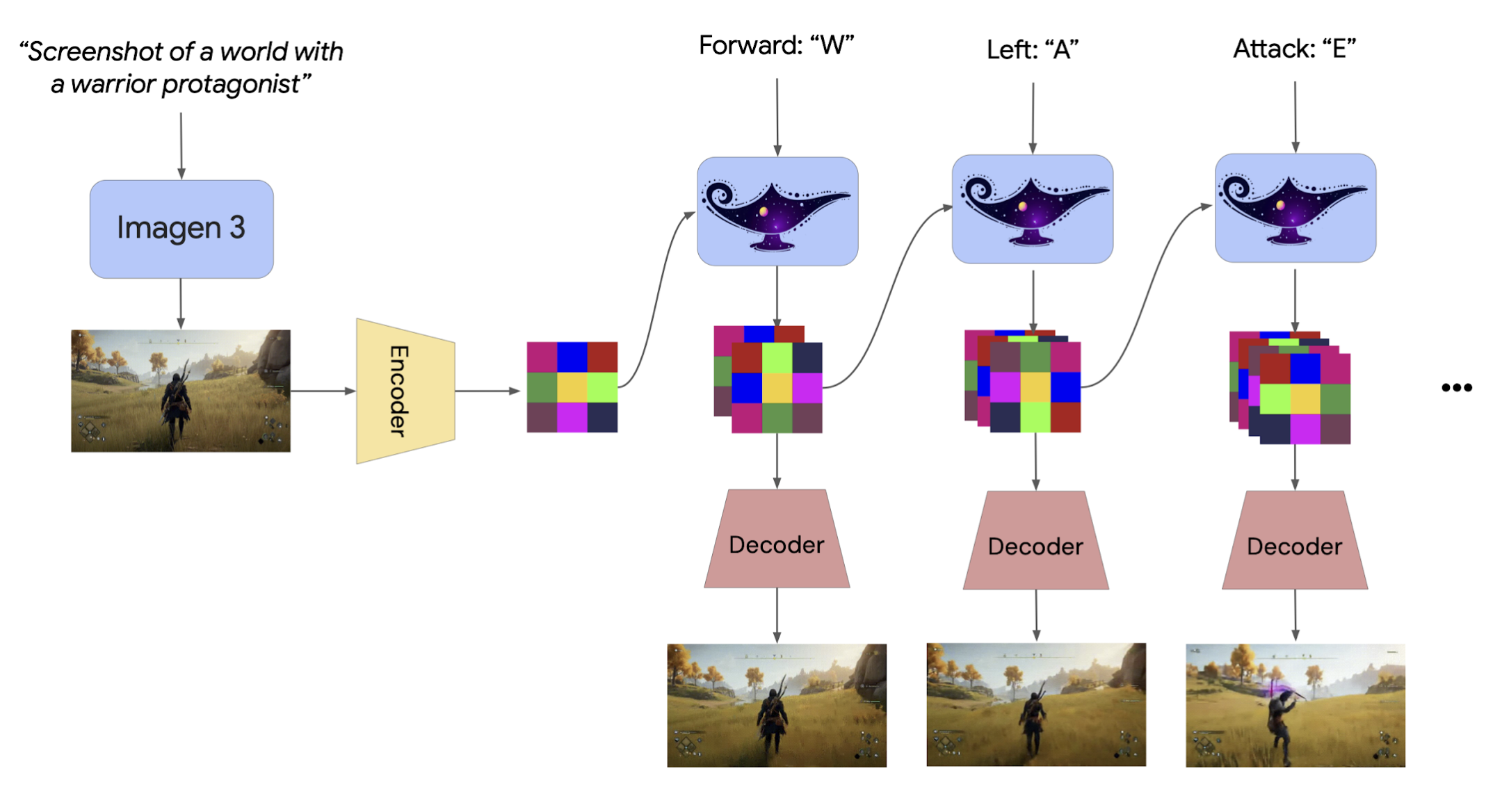
Figure 5. Overview of the diffusion world model used in Genie 2.
While the original Genie operated on discrete video tokens in 2D space, Genie 2 employs an autoregressive latent diffusion model
One of Genie 2’s most impressive capabilities is its ability to transform real-world photographs into interactive 3D environments. Show it a picture of a forest path, and it generates a navigable woodland where grass sways in the wind and leaves rustle overhead. Provide an image of a rushing river, and it creates a dynamic aquatic environment with flowing water and realistic fluid dynamics. This capability suggests that Genie 2 has developed sophisticated scene understanding that goes beyond simple pattern matching. The model appears to infer the three-dimensional structure of scenes, the likely physics governing environmental elements, and the potential interaction affordances—all from a single static image.
Figure 6. An environment concept by Max Cant transformed into a 3D world by Genie 2.
Interactive 3D worlds
More recently, DeepMind released Genie 3
Perhaps Genie 3’s most impressive advancement is its visual memory that remembers objects, textures, and even text for up to a minute. Turn away from a scene and look back—the world remains exactly as you left it, with objects in their previous positions and environmental details intact. This consistency enables longer storytelling sessions, complex navigation tasks, and meaningful interaction with persistent world elements. It’s the difference between a fleeting dream and a stable reality you can truly inhabit.
Figure 7. A demonstration of Genie 3’s visual memory, where the world remains consistent even when the camera is turned away.
Genie 3 also introduces promptable world events, where you can instantly transform the world (e.g., change the weather, add a character, or trigger an event) using natural language. These changes integrate seamlessly into the ongoing experience without breaking immersion or requiring scene resets. This capability also enables the generation of “what if” scenarios that can be learned by agents to handle unforeseen events.
Figure 8. With Genie 3, we can use natural language promps like “spawn a brown bear” to trigger events in the world.
The progression from Genie 1 to Genie 3 is mind-blowing considering that the timeframe was only about 1.5 years! Here’s a table comparing the features of the three generations:
| Feature | Genie 1 | Genie 2 | Genie 3 |
|---|---|---|---|
| Resolution | Low (2D sprites) | 360p | 720p |
| Control | Basic 2D actions | Limited keyboard/mouse actions | Navigation + promptable world events |
| Interaction latency | Not real-time | Not real-time | Real-time |
| Interaction horizon | Few seconds | 10–20 seconds | Multiple minutes |
| Visual memory | Minimal consistency | Minimal, scenes changed quickly | Remembers objects and details for ~1 minute |
| Scene consistency | 2D sprite coherence | Frequent visual shifts in 3D | Stable, believable 3D environments |
Waking up to a new reality
We stand at the threshold of a transformative era—one where the ancient human dream of creation becomes as accessible as natural language. The dream machines like Genie represent more than technological achievement. They herald a fundamental shift in how we conceive of digital creation, learning, and experience. Imagine:
- AI that learns like life evolved—trained in vast, dynamic worlds simulating billions of real-world experiences
This what Jeff Clune usually refers to as "Darwinian complete" search spaces, an environment that can generate any possible learning environment. , accelerating the path to true AGI through immersive, adaptive environments. - Creativity without limits—filmmakers, artists, and storytellers bringing entire worlds to life from a single sentence, turning imagination into interactive reality in real time.
- Education redefined—students stepping into history, medicine, or engineering challenges through lifelike simulations, mastering skills in safe, personalized, and endlessly adaptable virtual environments.
Yet perhaps the most exciting part is what we cannot yet imagine. We are likely only glimpsing the surface
If you could dream up any world and bring it to life, what would you create?
Citation
If you find this post useful, please cite it as:
Or in BibTeX format:
@article{suwandi2025dream,
title = "The Dream Machines",
author = "Suwandi, Richard Cornelius",
journal = "Posterior Update",
year = "2025",
month = "Aug",
url = "https://richardcsuwandi.github.io/blog/2025/dream-machines/"
}